从今天起正式开始学习py!!!
咸鱼了这么多天了终于开始搞点东西了
以下为学习新语言py的学习笔记~ 大概学的是python3
MD为什么看了这么多教程基本没一个顺眼能第一次找到想写的东西)
*夹带私货注意
唯一顺眼的 ->参考
基础语法
语句
首先,语句末尾没有’;’ 划重点
缩进
与c++不同,py里面是用缩进代替{}
例
if True:
print ("Answer")
print ("True")
else:
print ("Answer")
print ("False") # 缩进不一致,会导致运行错误
变量
python的数字变量
int整型 包括c++中的long long 舒服bool布尔型 这个都熟悉0,1判断float浮点数 包括c++中的float和double 应该没有精度限制complex复数 应该是高中那个i c++里面没用过不太清楚
python的字符串(以下为ctrl+c Ctrl+v)
- python中单引号和双引号使用完全相同。
- 使用三引号(‘’’或”””)可以指定一个多行字符串。
- 转义符 ‘\’
- 反斜杠可以用来转义,使用r可以让反斜杠不发生转义。。 如 r”this is a line with \n” 则\n会显示,并不是换行。
- 按字面意义级联字符串,如”this “ “is “ “string”会被自动转换为this is string。
- 字符串可以用 + 运算符连接在一起,用 * 运算符重复。
- Python 中的字符串有两种索引方式,从左往右以 0 开始,从右往左以 -1 开始。
- Python中的字符串不能改变。
- Python 没有单独的字符类型,一个字符就是长度为 1 的字符串。
- 字符串的截取的语法格式如下:变量[头下标:尾下标]

例子
str='Runoob'
print(str) # 输出字符串
print(str[0:-1]) # 输出第一个到倒数第二个的所有字符
print(str[0]) # 输出字符串第一个字符
print(str[2:5]) # 输出从第三个开始到第五个的字符
print(str[2:]) # 输出从第三个开始后的所有字符
# str[起始:结束:步长],范围包首不包尾
字符串倒读技巧
str[::-1]
字符串常用函数
str=' Hello, world! ' # 以下函数均不会改变原有的字符串,需要一个新的string/list/tuple 来进行储存
new=' '
newlist=[]
new=str.strip() # 'Hello, World!'
# .lstrip(),删除左侧的空白字符 .rstrip(),删除末尾的空白字符
new=str.replace('H','J',1) # 'Jello, world! ' 最后一个可以指定次数
newlist=str.split(',',1) # ['Hello', ' World!'] split函数自动返回一个新的列表,以’st'为分割符号,生成新的列表
newlist=list(str.partition(',')) # ['Hello',',',' world! ']
#该函数自动返回tuple 需要转一下类型
#该函数已指定字符做为一个部分,分割两边,生成三部分的字符串
# .capitalize(),将字符串第一个首字母大写(其它都小写)
# .title(),将字符串中所有单词首字母大写(其它都小写)
# .lower()转换所有大写字符为小写
# .upper()转换所有小写字符为大写
python 关键字
'False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield'
import keyword
print(keyword.kwlist)
读入
input()函数,感觉类似快读read() 其实只是长得像罢了
找了半天才了解到py读入默认字符串模式
要输入int 需要a=int(input())
py读入默认数字换行输入,不能空格
空格输入读入方法
x, y = map(int, input().split())
关于文件读入方式
- 整个文件读入(包括换行符)
with open('test.txt','r') as f :
data=f.read() # read() 所有一起读包括'\n'
f.readlines() # readlines() 一行行读入 不读换行符 自动去掉
f.readline() # readline() 读入'\n'
输出
py输出默认换行输出
print()注意不是printf
若不需要换行则end=" "
文件输出
doc= open('out.txt','w')
print('xxx',file=doc)
doc.close()
with open('out.txt','w') as f:
f.write('xxx') # 和read()相似 输出含'\n'
# 其他运用的例子
f = open('test1.txt', 'w')
f.writelines(["1", "2", "3"])
# 此时test1.txt的内容为:123
f= open('test1.txt', 'w')
f.writelines(["1\n", "2\n", "3\n"])
# 此时test1.txt的内容为:
# 1
# 2
# 3
赋值
py所有常量赋值不论什么类型都直接= 可以自己识别
例
counter = 2020 # 整型变量
miles = 2020.0803 # 浮点型变量
name = "AokiUmi" # 字符串
c++
int counter = 2020 # 整型变量
double miles= 2020.0803 # 浮点型变量
char name[] = "AokiUmi" # 字符串
允许多变量赋值
例a=b=c=2020 或a,b,c=2020.0803,'AokiUmi',2020
注释
三种语法
# 单行
'''
多行
'''
"""
多行2
"""
数据类型
number 和 string介绍过了
特别的是
- List(列表)可变
- Tuple(元组)不可变
- Set(集合)可变
- Dictionary(字典)可变
- Number(数字)不可变 这就意味着如果改变数字数据类型的值,将重新分配内存空间。
id()用于查询储存地址,若改变数值id会变 其实还是可以变 - String(字符串)不可变
这里的可变不可变指一次赋值完成后就不能再改
列表List
这个玩意好像很牛逼啊
可以数字,字符串混用6666
日常偷图 梅开二度
 变量[头下标:尾下标]
变量[头下标:尾下标]
这里注意单点更改/输出 看上面两行
区间更改/输出 看下面两行
和字符串一样+连接 * 复读
例如
list=['a',20,'error',2333.333]
# 0 1 2 3
# : 1 2 3 :
print(list[0]) # a
print(list[:2]) # ['a',20] : -> 2 指区间list[0] -> list[1]
list[1:2]=['AOKI','UMI','0315'] # 玄学操作出现了 py经竟能凭空插入列表,长度乱改 牛逼!
# ['a', 'AOKI', 'UMI', '0315', 'error', 2333.333] 此时列表凭空变长
# : 1 2 3 4 5 :
print(list) # ['a', 'AOKI', 'UMI', '0315', 'error', 2333.333]
list[4:]=['AOKI',2]
print(list[2:]) # ['UMI', '0315', 'AOKI', 2]
乱搞到这里py牛逼!
这就是py吗 i了i了 这比c++牛逼到哪里去了(bushi
List中的元素是可以改变的 这是重点 ,真滴好用。所以字符串,数字为啥改不了?挺迷惑的
list和string截取还有一种写法 ,引入了步长(长度参数)
lovelive = ['l','o','v','e','l','i','v','e']
# 0 1 2 3 4 5 6 7
# ---------
print(lovelive[1:5:2]) # ['o','e']
此写法不是截取一整段区间,而是打印出头尾字符
ps:该长度不包含最尾
print(lovelive[1:4:3])
print(lovelive[1:4:666])
# 输出都是['o']
del删除函数,能删除列表中的东西
既能单点也能区间
len(a) 求长度函数
list=[]
list.append('data') # 增加元素
# 常用遍历方法
for x in list:
print(x)
for i in range(len(list)) :
print(list[i])
还有很多函数就不列举了参考
| 方法 | 描述 |
|---|---|
| list.append(x) | 把一个元素添加到列表的结尾,相当于 a[len(a):] = [x]。 |
| list.extend(L) | 通过添加指定列表的所有元素来扩充列表,相当于 a[len(a):] = L。 |
| list.insert(i, x) | 在指定位置插入一个元素。第一个参数是准备插入到其前面的那个元素的索引,例如 a.insert(0, x) 会插入到整个列表之前,而 a.insert(len(a), x) 相当于 a.append(x) 。 |
| list.remove(x) | 删除列表中值为 x 的第一个元素。如果没有这样的元素,就会返回一个错误。 |
| list.pop([i]) | 从列表的指定位置移除元素,并将其返回。如果没有指定索引,a.pop()返回最后一个元素。元素随即从列表中被移除。(方法中 i 两边的方括号表示这个参数是可选的,而不是要求你输入一对方括号,你会经常在 Python 库参考手册中遇到这样的标记。)pop(1)删除第二个元素 |
| list.clear() | 移除列表中的所有项,等于del a[:]。 |
| list.index(x) | 返回列表中第一个值为 x 的元素的索引。如果没有匹配的元素就会返回一个错误。 |
| list.count(x) | 返回 x 在列表中出现的次数。 |
| list.sort() | 对列表中的元素进行排序。 |
| list.reverse() | 倒排列表中的元素。 |
| list.copy() | 返回列表的浅复制,等于a[:]。 |
元祖Tuple
据说这玩意和列表差不多,就是不能改?
定义方法 list用 []框起来,而元祖用()
虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。
例
tup=('love',['aoki',315],'live',12345) # 套娃牛逼
和list一样数字字符混用
额外语法
tup=() # 空
tup2=(2020,) # 一个元素,需要在元素后添加逗号
notice:
与字符串一样,元组的元素不能修改。
元组也可以被索引和切片,方法一样。
- 元组也可以使用+操作符进行拼接。
讲真这玩意不支持修改,真的有啥大用处吗?列表他不香吗?
集合set
定义方法 list用 []框起来,而set用{} 或者用set()用函数创建
例 a=set('1234567') ps: 此写法支持者一个长字符串
首先若是用{}来定义,套娃支持set套tup,list,dic
同时set()自带去重,自带字符串匹配算法。kmp白学啦爽啦!
例
b=set('aabbccdd')
print(b) # {'b', 'a', 'c', 'd'}
a=set('abcdaaasdsdscvcdcc')
print(a) # {'c', 'b', 'a', 'v', 's', 'd'}
说实话我没有看懂这个输出顺序以及set去重的算法原理,可能找人去问问)搞明白之后再写清楚
我在piazza上提问后我得到了明确的答复!
老师原文:
set in Python is implemented with the hash table as you mentioned [1]. It is basically a weaken version of dict which allows single values to be stored in it instead of key-value pairs.
Both the Python language specification and the semantics of the data structure hash table do not require set to be operated in a predictable order (i.e., deterministic). In the implementation [2] of the initializer of set, function set_update_internal is called to update the set you are creating with the iterable supplied. In the function, the interpreter is basically doing the hashing operation and insert the objects to the set. For security reasons [3], a randomized hash function is used in the interpreter which gives the object a non-deterministic property. The interesting thing is that the security fix is originally for the dict type. Since most of the implementation of set is just some kind of copy-paste from the implementation of dict, the fix that is originally for dict is kept in set. For dict, starting from version 3.6, a new implementation is proposed and used that could preserve the insertion order of KV pairs. But for some reason, the new implementation is not yet applied to set.
In short, the non-deterministic property is caused by the randomized hash function used in the CPython interpreter. The language specification does not guarantee you as a user to expect a deterministic set implementation. But the situation may change from version to version.
翻译成人话就是用的确实是hash就是用了随机化数组输出,为了保证用户安全啥啥玩意 挺离谱的)
关于字符串匹配内置算法
a = set('aabbccdd')
b = set('abcdaaasdsdscvcdcc')
print(a-b) # a和b的差集
print(a|b) # a和b的并集
print(a&b) # a和b的交集
print(a^b) # a和b中不同时存在的元素
# set() 若是b-a则是 {'s', 'v'}
# {'s', 'a', 'v', 'd', 'b', 'c'}
# {'c', 'a', 'b', 'd'}
# {'s', 'v'}
这个运算应该是直接根据set去重之后的结果进行简单的比较打标比较就完了用不到字典树,kmp这种高级玩意)
集合同样支持删除和增加
s.update() s.add()
s.remove()如果元素不存在,则会发生错误。
s.discard() 如果元素不存在,不会发生错误
s.pop() 随机删元素?md绝了,你当我抽卡呢?
更多函数请见 教程
set不支持遍历,下标读取等操作,需要谨慎使用
字典dictionary
dictionary与list区别看一看做list就是可以装各种东西的数组,下表都是固定的从0-?话说这些类似数组的东西储存空间有多大啊)突然迷惑
dictionary给我的感觉就是更加智能的数组,下标自定义,装的东西也非常丰富,好牛。
dic['aoki']=315
dic['园田海未']='wife' # 单点命名
dic={'aoki': 315,'园田海未': 'wife'} # 多点命名
dict([('aoki',315),('园田海未','wife')])# 此函数 直接输出用好像
dict(aoki=315,umi=wife)# 此函数 直接输出用好像
内置函数介绍
print(dic.keys()) # 输出键 下标
print(dic.values()) # 输出内容
dic.clear() # 清楚
感觉这几个很像c++的string ,指函数写法
用字典来打标
dic={}
for i in range(len(data)) :
dic[data[i]]=[0,0] # dic套list写法 初始化先把list都赋值
dic[data[i]]=0 # 普通的初始化
for i in range(len(data)) :
dic[data[i]][0]+=x
dic[data[i]][1]+=1
#这样就能打标了
# ps list,tuple不能用来打标) list不好搞 tuple不能改变
notice:
- 字典的关键字必须为不可变类型,且不能重复。好理解下标嘛
- 创建空字典使用 { }。
list与dic添加操作区分
list.append(x) # append一个值是可以重复添加的
dic[ch]=x dic.update({ch :x}) # dic中的key不可改变 若多次update相同的key 就会覆盖掉前面的
# 所以dic能用来打标 list不行
关于这几个类似数组的东西的储存空间
好像都是电脑默认最大储存值,和c++ (1<<30)那个不太一样吧,可能py没有爆空间的忧虑,很方便
运算符
常规与c++ 一致 不同的有
算术运算符
** 乘方(自带ksm?)
// 取整除
赋值运算符
**= 乘方赋值
//= 取整除赋值
:= 海象运算符,可在表达式内部为变量赋值。Python3.8 版本新增运算符。
例子 if (n := len(a)) > 10:
比较运算符
新增 is&is not 能比较数值和类型
== 只比较数值
1 == 1.0
True
1 is 1.0
False
1 !=1.0
False
1 is not 1.0
True
位运算符
& binary AND – For a digit, if any number is 0, result is 0
| binary OR – For a digit, if any number is 1, result is
和c++一样呢懒得翻译了(bushi
逻辑运算符
在python里面,0、’’、[]、()、{}、None为假,其它任何东西都为真
Python语言支持逻辑运算符,以下假设变量 a 为 10, b为 20:
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔”与” - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。 | (a and b) 返回 20。 |
| or | x or y | 布尔”或” - 如果 x 是 True,它返回 x 的值,否则它返回 y 的计算值。 | (a or b) 返回 10。 |
| not | not x | 布尔”非” - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
优先级or>and>not
not优先级低于非布尔运算符
成员运算符
in 判断该成员是否在制定序列中
not in同理
运算符优先级
| 运算符 | 描述 | |
|---|---|---|
| ** | 指数 (最高优先级) | |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) | |
| * / % // | 乘,除,求余数和取整除 | |
| + - | 加法减法 | |
| >> << | 右移,左移运算符 | |
| & | 位 ‘AND’ | |
| ^ \ | 位运算符 | |
| <= < > >= | 比较运算符 | |
| == != | 等于运算符 | |
| = %= /= //= -= += *= **= | 赋值运算符 | |
| is is not | 身份运算符 | |
| in not in | 成员运算符 | |
| not and or | 逻辑运算符 |
整型相关函数
| 函数 | 描述 |
|---|---|
| int(x) | 将x转换为一个整数 |
| float(x) | 将x转换到一个浮点数 |
| complex(x) | 创建一个复数 |
| complex(x, y) | 将 x 和 y 转换到一个复数,实数部分为 x,虚数部分为 y。x 和 y 是数字表达式。 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(s) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个 (key, value)元组序列。 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
数学函数
| 函数 | 返回值 ( 描述 ) |
|---|---|
| abs(x) | 返回数字的绝对值,如abs(-10) 返回 10 |
| ceil(x) | 返回数字的上入整数,如math.ceil(4.1) 返回 5 |
| cmp(x, y) | 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1。 Python 3 已废弃,使用 (x>y)-(x<y) 替换。 |
| exp(x) | 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045 |
| fabs(x) | 返回数字的绝对值,如math.fabs(-10) 返回10.0 |
| floor(x) | 返回数字的下舍整数,如math.floor(4.9)返回 4 |
| log(x) | 如math.log(math.e)返回1.0,math.log(100,10)返回2.0 |
| log10(x) | 返回以10为基数的x的对数,如math.log10(100)返回 2.0 |
| max(x1, x2,…) | 返回给定参数的最大值,参数可以为序列。 |
| min(x1, x2,…) | 返回给定参数的最小值,参数可以为序列。 |
| modf(x) | 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。 |
| pow(x, y) | x**y 运算后的值。 |
| round(x [,n]) | 返回浮点数 x 的四舍五入值,如给出 n 值,则代表舍入到小数点后的位数。其实准确的说是保留值将保留到离上一位更近的一端。 |
| sqrt(x) | 返回数字x的平方根。 |
其他见不常用函数
进阶编写
所有东西后面:很重要千万别忘了
循环语句
- for循环
for i in range(1, 10, 3): # = for(int i=1;i<10;i+=3)
for i in range(10): # for(int i=0;i<10;i++)
a= ['Aoki','Umi','0315']
for i in range(len(a)) : # 遍历list 很慢千万别用)
for i in a : # 这个好
# : 别忘了
- while循环
while a<=10 :
# operation
else :
break
continue
条件控制
if a >=2 :
# operation
elif a< 1 :
# operation
else :
# operation
函数自定义
def aoki(umi, wife) : # 变量
# operation
return
def aoki(umi :str ,wife : int) # 定义变量类型
def aoki(*p ) #放入list or tuple
def aoki(**p) # 放入字典形式
迭代器与生成器
assert断言
断言顾名思义
就是如果你的判断语句返回是否,程序终止进行并输出你想要的语句
def Div(x,y):
assert y!=0,"denominator is 0"
return x/y
print(Div(1,0))
# Traceback (most recent call last):
# File "d:\personal\homework\try\try.py", line 4, in <module>
# print(Div(1,0))
# File "d:\personal\homework\try\try.py", line 2, in Div
# assert y!=0,"denominator is 0"
# AssertionError: denominator is 0
匿名函数
lambda匿名函数,目前觉得在排序中用的很多 可以处理多key排序
主要是list,dic里面排序用的
首先list自带排序
ans.sort(key=lambda s:(s[1] ,s[0]),revese=True) # 先按s[1],再s[0] revese表示升序还是降序,默认升序
ans.sort(key=lambda s:(-s[1] ,s[0])) # s[1]降 s[0]升
class类
py中的结构体 称class 定义比c++麻烦很多,但仍然需要掌握
类的属性:封装性,继承性,多态性
判断一个对象是不是一个class isinstance(x,demo) isinstance(demo,type)
封装性
class aoki:
value="aoki_umi" #类变量
def __init__ (self ,name ,age ) :
self.name=name
self.age=age # 初始化自定义结构体的数值
def __init__ (self) :
self.name=None
self.age=None # 与前者的区别是后者数据可以为空
def __init__ (self,v) : # 推荐写法
self.name=v
self.value='AOKI_UMI'
def pri(self) : # 类中自定义函数 这个self好像必须写上去
return self.name
def opr(x ,v) : #在外面定义函数使用class aoki
x.name=v
#class的自定义属性可以动态改变
#以第三种写法为例
AOKI=aoki('umi')
AOKI.love='love'
print(AOKI.love,AOKI.name) #不会报错
del AOKI.name
print(AOKI.love,AOKI.name) #会报错
print(aoki.value) # aoki_umi
print(AOKI.value) # AOKI_UMI
opr(AOKI,'2323')
继承性
python支持不同类的套娃调用,还能支持多次套娃调用
很牛逼的地方就在于它的多次调用,这里面多次调用的内置顺序就是dfs和bfs
该说明搬运参考
传统的类的调用使用dfs
新类(object)使用bfs
盗的图x
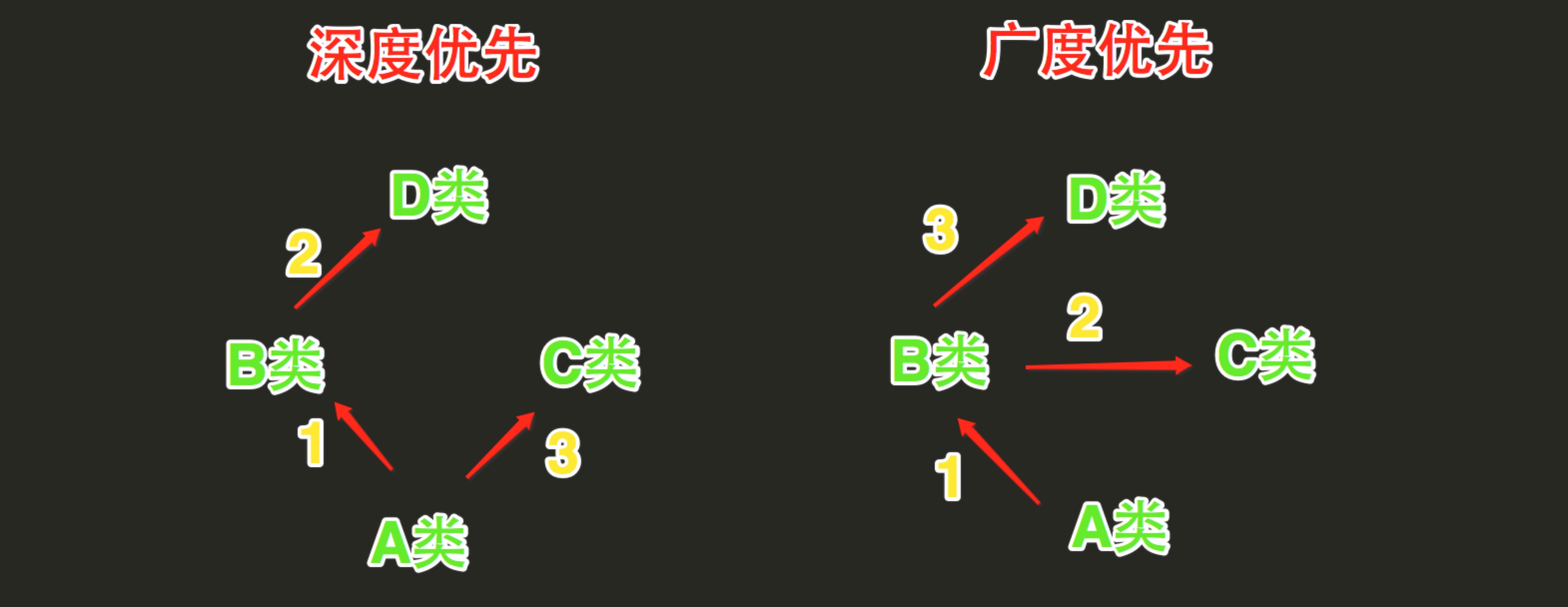
标准类
class D:
def bar_D(self):
print ('D.bar')
class C(D):
def bar_C(self):
print ('C.bar')
class B(D):
def bar_B(self):
print('B.bar' )
class A(B, C):
def bar_A(self):
print ('A.bar')
a = A()
# 执行bar方法时
# 首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去D类中找,如果D类中么有,则继续去C类中找,如果还是未找到,则报错
# 所以,查找顺序:A --> B --> D --> C
# 在上述查找bar方法的过程中,一旦找到,则寻找过程立即中断,便不会再继续找了
a.bar_B()
新类
class D(object):
def bar_D(self):
print ('D.bar')
class C(D):
def bar_C(self):
print ('C.bar')
class B(D):
def bar_B(self):
print ('B.bar')
class A(B, C):
def bar_A(self):
print ('A.bar')
a = A()
# 执行bar方法时
# 首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去C类中找,如果C类中么有,则继续去D类中找,如果还是未找到,则报错
# 所以,查找顺序:A --> B --> C --> D
# 在上述查找bar方法的过程中,一旦找到,则寻找过程立即中断,便不会再继续找了
a.bar_C()
多态性
多态性是指具有不同功能的函数可以使用相同的函数名,这样就可以用一个函数名调用不同内容的函数。在面向对象方法中一般是这样表述多态性:向不同的对象发送同一条消息,不同的对象在接收时会产生不同的行为(即方法)。也就是说,每个对象可以用自己的方式去响应共同的消息。所谓消息,就是调用函数,不同的行为就是指不同的实现,即执行不同的函数。
就是说不同的类里面可以用相同的自带函数名
#多态:同一种事物的多种形态,动物分为人类,猪类(在定义角度)
class Animal:
def run(self):
raise AttributeError('子类必须实现这个方法')
class People(Animal):
def run(self):
print('人正在走')
class Pig(Animal):
def run(self):
print('pig is walking')
class Dog(Animal):
def run(self):
print('dog is running')
def func(ANIMAL): #参数animal就是对态性的体现
ANIMAL.run()
people1=People() #产生一个人的对象
pig1=Pig() #产生一个猪的对象
dog1=Dog() #产生一个狗的对象
func(people1)
func(pig1)
func(dog1)
重载运算符
以下为可以重载的函数(运算符)
构造和析构
__init____del__
函数调用
__call__
打印操作
__str____repr__
str(x), print(X):会先尝试__str__方法,然后尝试__repr__方法;repr(X)或交互模式下输入X,只会尝试__repr__方法。
属性操作
__getattr__:只有类中没有定义的属性点号运算才会尝试该方法__setattr__:类中所有属性的赋值语句都会尝试该方法,self.attr=val会变self.setattr('attr',val)
__delattr____getattribute__:类中所有属性的点号运算都会尝试该方法
索引与分片
__getitem____setitem____delitem__
迭代环境
__iter____next__
在所有的迭代环境中,会先尝试__iter__方法,然后在尝试__getitem__方法,但是注意迭代器根本没有重载索引表达式,所以如果需要通过while来根据下标手工迭代,那么需要定义__getitem__方法。
成员测试
__contains__
in成员测试会先尝试contains方法,然后是__iter__方法,最后是__getitem__方法。
描述符属性
__get____set____delete__
主要这里是__delete__,也析构函数__del__是完全不同的。
比较大小
__lt____le____gt____ge____eq__: !=和==都会尝试该方法,所以需要确保两个运算符都正确地作用。
请看下面的实例:
class X:
def __init__(self, value):
self.data = value
def __eq__(self, value):
return self.data == value
x = X(4)
print(x ==5)
print(x != 5)
结果为
False
True
数学运算操作
__add__, __iadd__, __radd____sub__, __isub__, __rsub____mul__, __imul__:乘法__neg__, __pos__:表示-obj, +obj__abs____floordiv__, __ifloordiv__, __truediv__, __itruediv____mod__, __imod__, __imod____pow__, __ipow__
a += b会尝试增强加法__iadd__,然后尝试普通加法__add__
x = b + obj:如果b不是类实例时,会调用右侧加法__radd__
当我们把两个实例相加的时候,Python运行__add__,它反过来通过简化左边的运算数来触发__radd__。
对象运算操作
__concat__:比如序列a,b的加法a+b__iconcat__
位运算符
__and__, __iand____or__, __ior__, __xor__, __ixor____inv__, __invert__ : ~obj__lshift__, __ilshift__, __rshift__, __irshift__
a &=b:会先尝试__iand__,然后尝试__add__
布尔测试
__bool____len__
布尔测试会先尝试一个特定的__bool__方法,然后在尝试__len__方法。在Python2.6中使用的名称不是__bool__,而是__nonzero__
环境管理
主要是用于with语句的上下文管理。__enter____exit__
用来定义类
__new__
这个函数会在类初始化函数__init__之前调用
整数值
__index__
如果在bin(X), hex(X), oct(X), O[X], O[X:]等需要传入一个数字、索引、分片的值时传入一个对象,那么该对象的__index__会被调用。
主要是用来替代Python2.x中的__oct__, __hex__
举个栗子
# 第一个写法是加入了保护变量的写法
class Vector:
def __init__(self,v) :
self.__value=v
self.__length=len(v)
def __getitem__(self,index) :
return self.__value[index]
def __setitem__(self,index,item) :
self.__value[index]=item
def getDim(self) :
return self.__length
def __add__(self,other) :
target=self.__value.copy()
for i in range(self.__length) :
target[i]+=other.__value[i]
return Vector( target)
def __sub__(self,other) :
target=self.__value.copy()
for i in range(self.__length) :
target[i]-=other.__value[i]
return Vector( target)
def __mul__(self,other) :
target=self.__value.copy()
for i in range(self.__length) :
target[i]*=other
return Vector( target)
def __truediv__(self,other) :
target=self.__value.copy()
for i in range(self.__length) :
target[i]/=other
return Vector( target)
def getlength(self) :
l=0
for i in self.__value :
l+=i
return l
def __str__(self) :
s=''
for i in range(self.__length-1) :
s+='{'+str(self.__value[i])+'},'
s+='{'+str(self.__value[i])+'}'
return 'Vector('+s+')'
# 第二个不带锁定
class Vector:
def __init__(self,v) :
self.value=v
self.length=len(v)
def __add__(self,other) :
target=self.value.copy()
for i in range(self.length) :
target[i]+=other.value[i]
return Vector( target)
def __sub__(self,other) :
target=self.value.copy()
for i in range(self.length) :
target[i]-=other.value[i]
return Vector( target)
def __mul__(self,other) :
target=self.value.copy()
for i in range(self.length) :
target[i]*=other
return Vector(target)
def __truediv__(self,other) :
target=self.value.copy()
for i in range(self.length) :
target[i]/=other
return Vector( target)
def getlength(self) :
l=0
for i in self.value :
l+=i
return l
def __str__(self) :
s=''
for i in range(self.length-1) :
s+='{'+str(self.value[i])+'},'
s+='{'+str(self.value[i])+'}'
return 'Vector('+s+')'
A=Vector([1,2,3])
B=Vector([4,5,6])
print(A)
print(A+B)
print(A-B)
print(A*5)
print(B/2)
print(A.getlength())
Try使用
try也可以看成是一种if条件语句
但try有很多错误类型可以根据以下Exception hierarchy中类型进行判断
Exception hierarchy
Exception hierarchy (异常继承关系)
###########################################################################
BaseException (基本异常)
+-- SystemExit (系统退出)
+-- KeyboardInterrupt (键盘中断)
+-- GeneratorExit (生成器退出)
+-- Exception (异常)
+-- StopIteration (停止迭代)
+-- StopAsyncIteration (停止不同步迭代)
+-- ArithmeticError (代数错误)
| +-- FloatingPointError (浮点错误)
| +-- OverflowError (溢出错误)
| +-- ZeroDivisionError (除零错误)
+-- AssertionError (声明错误)
+-- AttributeError (属性错误)
+-- BufferError (缓冲错误)
+-- EOFError (文件结束符错误)
+-- ImportError (导入错误)
| +-- ModuleNotFoundError (模块没有找到错误)
+-- LookupError (查找错误)
| +-- IndexError (索引错误)
| +-- KeyError (关键字错误)
+-- MemoryError (内存错误)
+-- NameError (命名错误)
| +-- UnboundLocalError (没有边界局域错误)
+-- OSError (操作系统错误)
| +-- BlockingIOError (锁定IO错误)
| +-- ChildProcessError (子进程错误)
| +-- ConnectionError (连接错误)
| | +-- BrokenPipeError (打破管道错误)
| | +-- ConnectionAbortedError (连接失败错误)
| | +-- ConnectionRefusedError (连接拒绝错误)
| | +-- ConnectionResetError (连接重置错误)
| +-- FileExistsError (文件存在错误)
| +-- FileNotFoundError (文件没有找到错误)
| +-- InterruptedError (中断错误)
| +-- IsADirectoryError (是目录错误)
| +-- NotADirectoryError (不是目录错误)
| +-- PermissionError (允许错误)
| +-- ProcessLookupError (进程查找错误)
| +-- TimeoutError (超时错误)
+-- ReferenceError (参考错误)
+-- RuntimeError (运行时错误)
| +-- NotImplementedError (不是应用错误)
| +-- RecursionError (递归错误)
+-- SyntaxError (格式错误)
| +-- IndentationError (缩进错误)
| +-- TabError (Tab错误)
+-- SystemError (系统错误)
+-- TypeError (格式错误)
+-- ValueError (值错误)
| +-- UnicodeError (U编码错误)
| +-- UnicodeDecodeError (U解编码错误)
| +-- UnicodeEncodeError (U编码错误)
| +-- UnicodeTranslateError (U翻译错误)
+-- Warning (警告)
+-- DeprecationWarning (反对警告)
+-- PendingDeprecationWarning (挂起反对警告)
+-- RuntimeWarning (运行警告)
+-- SyntaxWarning (格式警告)
+-- UserWarning (用户警告)
+-- FutureWarning (未来警告)
+-- ImportWarning (导入警告)
+-- UnicodeWarning (U编码警告)
+-- BytesWarning (字节警告)
+-- ResourceWarning (资源警告)
运用实例
try的判断好像很有趣 比如下面例子在除0时遇到错误,foo里面不会执行print("try-2")语句
会跳转到except里面判断错误类型是否符合若符合则进入except,但无论如何finally里面语句都会执行
用来证明该try判断已经执行过了
挺有趣的
def foo(a,b) :
try:
x=a/b
print("try-2")
except AssertionError :
print("except-A")
return
finally :
print("final-1")
try:
foo(1,0)
except ZeroDivisionError :
print("except-2")
else:
print("else-2")
finally:
print("finally-2")
不实用的东西global&nonlocal
global 定义变量表示所有函数外的全局变量
nonlocal 定义上一个在函数中定义的x nonlocal不能调用global 会报错哦
反正就这意思 懂得都懂应付考试用的
global y
def foo():
x=1
def bar():
x=2
def baz():
nonlocal x
print(x) # 2
global y
y=3
baz()
bar()
foo()
print(y) # 3
global y
def foo():
x=1
def bar():
def baz():
nonlocal x
print(x) # 1
baz()
bar()
foo()
常用包介绍
Numpy
numpy好像是主要在多维数组,大数据的处理上有非常大的用处
ndarray,具有矢量运算能力,快速、节省空间。numpy支持高级大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
import numpy as np
data=[[1,2,3,4],[2,3,4,5]]
a=np.array(data)
print(a)
# array([[1, 2, 3, 4],
# [5, 6, 7, 8]])
np.zeros(5,6)# 创建一个5行6列的0数组
np.array([np.arange(2,5),np.arange(4,7)]) # [[2, 3, 4], [4, 5, 6]]
a.ndim #dimension 2
a.shape # 2x4
a.dtype #int64
究极乱搞
py这种神仙东西只用来写普通代码不搞事真的是太浪费了)
乱搞的小型爬虫
爬我自己 博客文章标题)只支持一页页的爬
我爬我自己
import requests
from bs4 import BeautifulSoup
title = []
small_thing =[]
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def fillUnivList(soup):
tit = soup.find_all('h2')
for h2 in tit:
title.append(h2.string)
cate=soup.find_all('h6')
for h6 in cate:
small_thing.append(h6.string)
def printUnivList():
doc = open('out.txt','w')
for i in range(len(title)):
u=title[i]
print(u,file=doc)
for i in range(len(small_thing)):
print(small_thing[i],file=doc)
doc.close()
def get_title(url):
html = getHTMLText(url)
soup = BeautifulSoup(html, "html.parser")
fillUnivList(soup)
printUnivList()
def main():
get_title('https://aokiumi.github.io')
main()